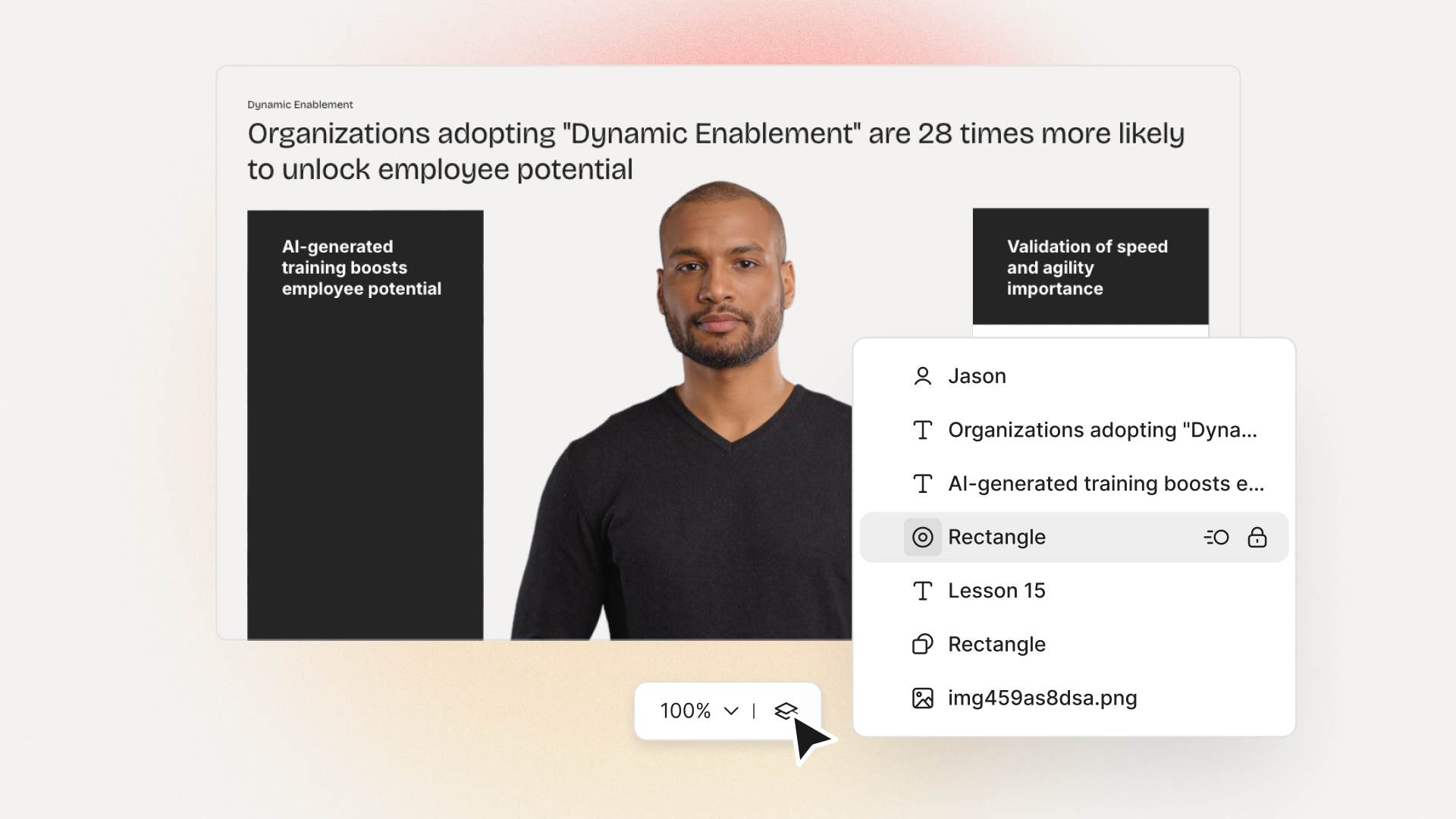
Colossyan is a synthetic media company that provides a world-class video-editing platform that uses AI actors to tell your story. These AI avatars allow you to facilitate human connection while also creating large amounts of content at scale.
Colossyan is a powerful tool with many different feature offerings – and more constantly being added. We built our tech stack by leveraging different open source AI solutions, trained with our actors, built into a complete SaaS product.
In this blog, we'll provide a glimpse into the engineering problems and solutions we encounter at Colossyan.
Introduction to AI video generation
AI video generation is a rapidly evolving field that leverages artificial intelligence and machine learning to create high-quality videos. This cutting-edge technology has a wide range of applications, from training videos to social media content creation and more.
By automating the video creation process, an AI video generator allows you to create more engaging content more quickly and cost effectively than traditional videos. With an AI avatar as your video host, you won't have to hire human actors, spend hours filming them, and even more time editing all of your footage together. Instead, you can skip the lengthy and manual video creation process with a text-to-speech AI actors, allowing you to create content in minutes instead of weeks.
This technology not only streamlines the video production process, but also opens up opportunities for creative storytelling and interactive content that wouldn't be possible with a traditional video.
Colossyan is a powerful AI video generator that helps you quickly create engaging videos
What are AI actors?
Before we jump to the full stack, let's talk about the heart of our product: the AI actors.
Different AI models such as our actors require compute power to run. Usually these models compromise on either quality and speed: the better the quality of the actor, the longer a user has to wait for it to be generated. Also, the underlying compute resources can vary a lot based on what the chosen (cloud) provider can offer.
As GPUs are also quite expensive in the cloud, we have to own a flexible setup: autoscaling of instances using GPUs is a must for any company running AI models at scale in production.
We use AWS, and we run G4 EC2 instances that have GPUs in it. For automatic scaling we leverage AWS ECS, and taking it one step further we benefit from AWS Batch for batch processing the work. We did not immediately start off with stream based processing as GPU-based instance scaling is still a bottleneck most of the time. However as our models and other parts of the stack are being improved, we get closer and closer to achieving real-time actor synthetisation.
Colossyan currently offers a diverse range of more than 150 AI avatars to choose from on our platform. These AI actors are ready to be used in your videos, so you're able to select whichever actor best represents your audience or message.
Besides all the actor AI models, there are plenty of well-known industry-standard components that we build our stack upon. From the top to the bottom, our React UI kit was brought to the customers at a very fast pace – just check out our changelog powered by Canny. There's usually a major UI update every 2 weeks.
Our web backend and API is bundled in a NodeJS container, orchestrated in Kubernetes. Kubernetes comes with a lot of features to ship our product easily (like rolling upgrades), and also many auxiliary services help us in our everyday work: Prometheus for monitoring, Nginx for ingress, logging, etc.
Our product metrics related analytics platform is Mixpanel, providing us with a lot of insights. We pay significant attention to the numbers and raise the bar higher and higher every week. We are actively monitoring many product-related metrics and detecting any anomalies that occur.
Our infrastructure has just recently been put to the test: our Hide the pain Harold prank video campaign. We peaked at several thousand of videos generated in a single day, without major interruption or more than 15 minutes queueing time, but that story will be told in a future blog post.
Hide the pain Harold's prank
The future of our AI tech stack
We’ll actively work on creating proper SLAs in the future, by the time we reach product maturity we have to get ready to provide an excellent service to our customers. Failed video generation or major UI flaws all fall into this category.
There are also plenty of new features in our roadmap. From an engineering perspective they differ in complexity, we will uncover them in later blog posts.
What's next?
Want to know how AI models are assembled? How were we able to improve the scalability and robustness of the system? Stay tuned, and follow our channel to get notified about our upcoming blog posts that will dive deep into many more engineering topics!
Adam leads Colossyan's microservices and infrastructure teams, which are responsible for the development of Colossyan's AI video generation engine and infrastructure. He lives in Budapest.
Networking and Relationship Building
Use this template to produce videos on best practices for relationship building at work.
Oops! Something went wrong while submitting the form.
example
Thank you - your video is on its way!
If you’d like to try out Colossyan and create a video yourself, just visit our website on your desktop and sign up for a free account in seconds. Until then, feel free to check out our examples.












.avif)





%20(1).avif)



.webp)

