Technical Deep Dive
February 2026 by Colossyan Research Team
Beyond Lip-Sync: Robust Video Dubbing
Most lip-sync models break the moment conditions get difficult. Colossyan Dubbing handles real-world footage as it actually exists, not as a controlled studio setup pretends it does, by feeding the full frame through the NEO 2 architecture instead of a narrow crop of the mouth.
Different speakers, different scenes
The same model on footage we did not control. Every sample dubs a voiced source into a new language with lip motion preserved.
Original
Dubbed
Sample 01
Documentary b-roll
Handheld camera, head turns, hair across face
🇬🇧 EN
Click for sound
🇵🇱 PL
Click for sound
Sample 02
Webcam call
Low-resolution source, mixed lighting
🇬🇧 EN
Click for sound
🇫🇮 FI
Click for sound
Sample 03
Conference keynote
Stage lighting, distant camera, mic in frame
🇬🇧 EN
Click for sound
🇫🇷 FR
Click for sound
Sample 04
Auditorium keynote
Long-shot framing, off-axis camera, audience in view
🇬🇧 EN
Click for sound
🇫🇷 FR
Click for sound
Where every other model gives up
The conditions below are exactly the ones that break crop-based lip-sync tools. We pointed Colossyan Dubbing at each one.
Dubbing Has Always Been a Compromise
Traditional video dubbing forces a choice: accept mismatched lip movements, or reshoot the entire video. AI-driven lip-sync tools promised a third option, algorithmically adjusting the speaker's mouth to match new audio. In practice, most of them fail the moment conditions get difficult.
A shadow falls across the speaker's face. They turn to glance at a colleague. A microphone drifts in front of their chin. A strand of hair crosses their lips. In any of these situations that occur constantly in real-world footage, existing lip-sync models produce artefacts, flicker, or give up.
We built something that does not. Colossyan Dubbing is a video dubbing model that works on raw footage, not just clean studio captures. And it is powered entirely by NEO 2.
What Makes This Different
Most lip-sync models operate on a narrow crop of the mouth region. They detect the lips, modify them in isolation, and paste the result back. We do not crop. We do not isolate. We pass the full frame through the model.
Full Frame, Not a Crop
The model sees the entire scene, lighting, pose, and background, instead of a narrow strip around the mouth.
Identity Preserved
Clothing, lighting, environment, and motion stay identical. Only the lips and jaw move to match the new audio.
Temporally Coherent
NEO 2's sequence-aware architecture means no per-frame flicker. The dubbed output is as stable as the source.
Lighting & Geometry Aware
Shadows fall correctly when the jaw moves. Skin texture shifts naturally. Pixels stay consistent with the surrounding scene.
Español
Polski
日本語
Deutsch
Architecture
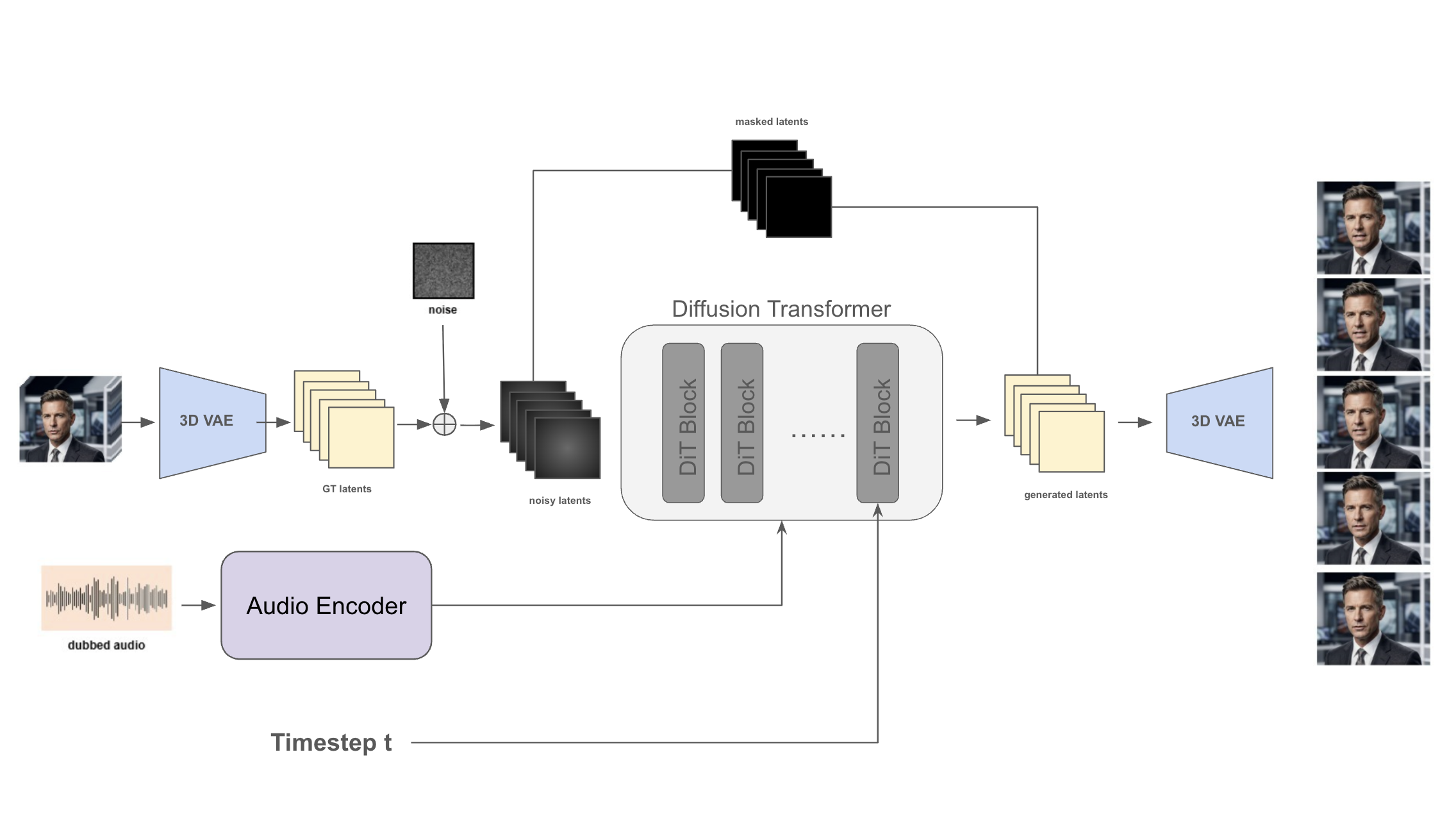
How It Works: NEO 2 Under the Hood
The architecture takes the proven generative power of NEO 2 and applies it to the dubbing problem. For each frame sequence, the model receives the original video and the new dubbed audio, then re-renders the lower face region in context.
1. Conditioning on the Original
Most generative video models start from noise and produce something new. Dubbing is a different problem: the answer is mostly already in the source. So instead of generating a person from scratch, NEO 2's Diffusion Transformer is conditioned on the original video itself, preserving identity, clothing, environment, lighting, and motion. Only what needs to change, the lip and jaw movements, gets re-generated.
2. Selective Re-rendering
Because the DiT attends to the full spatial context of every frame, it understands how light falls across the face, where shadows should land when the jaw moves, and how skin texture should shift with expression. The model does not just redraw the lips. It re-renders the entire lower face region in context, ensuring every pixel is consistent with the surrounding scene.
- The mouth, jaw, and surrounding skin are regenerated as a coherent region, not a crop.
- Cast shadows from the chin and lower lip are adjusted to match the new motion.
- Highlights, skin texture, and stubble carry over from the original.
3. Temporal Coherence
NEO 2's temporal architecture processes frames as a sequence rather than independently. The model knows what the speaker looked like a moment ago, so the dubbed output maintains the same natural motion continuity as the original footage. There is no per-frame flicker. No temporal inconsistency. The dubbed version feels as stable and grounded as the source.
Click for sound
Built for the Real World
The defining feature of Colossyan Dubbing is not accuracy in ideal conditions; it is robustness. The ability to produce clean, convincing results in conditions where every other tool breaks down.
Lighting changes
Shadows that fall across the face, harsh outdoor sun, mixed colour temperature. The model sees the lighting environment and matches it as the jaw moves.
Occlusion
A microphone, a strand of hair, a hand near the face. The model reasons about what is in front of the lips, not just what the lips look like.
Head angle and perspective
Profile views, glances away from camera, full head turns. Because the model never crops the mouth, perspective changes don't break the geometry.
Motion blur and camera dynamics
Handheld footage, walking shots, fast cuts. The temporal architecture stays grounded across the whole sequence.
The Bottom Line
Good video dubbing should be invisible. The audience shouldn't be able to tell it happened. To get there, the model has to treat the lips as part of a face and a scene, not as a region to patch in isolation.
That's what NEO 2 makes possible. Instead of filtering a cropped mouth, the model re-renders the lower face using the full frame and the frames around it as context.
The result is a dubbed video that looks like it was shot that way.
Early Access
Get early access to the Dubbing API
We're rolling out Colossyan Dubbing to teams in waves. If you're building something that needs broadcast-quality dubbing on real-world footage, drop your details and we'll be in touch as we open access.
FAQ
Frequently Asked Questions
Colossyan Dubbing is a video dubbing model that takes a source video and a new audio track and produces a version where the speaker's lips, jaw, and lower face match the dubbed audio. Unlike traditional lip-sync tools that crop the mouth region and modify it in isolation, Colossyan Dubbing passes the full frame through the NEO 2 architecture, so the output stays consistent with the lighting, geometry, and motion of the surrounding scene.
Most lip-sync models operate on a narrow crop of the mouth region. They detect the lips, modify them in isolation, and paste the result back, which fails the moment something changes around the mouth: a shadow, a microphone, a head turn, a strand of hair. Colossyan Dubbing never crops. The model sees the entire scene and re-renders the lower face in full context, so it works on real-world footage that breaks every other tool.
Colossyan Dubbing was designed for raw, unprocessed footage. Conference recordings, outdoor interviews, documentary b-roll, webcam calls, handheld shots. The model handles changing light, occlusion, head turns, and motion blur because NEO 2's full-frame conditioning gives it the surrounding context it needs. Studio-clean footage works too, but the real value is in the cases where every other tool fails.
Yes. The dubbing model uses the same NEO 2 Diffusion Transformer that powers Colossyan's full-body avatar generation. The difference is in conditioning: instead of generating a person from scratch, the DiT is conditioned on the original video, preserving identity, clothing, environment, lighting, and motion, and selectively re-rendering only the lip and jaw region to match the new audio.
Yes. Because the model is conditioned on the original video, the speaker's appearance, clothing, environment, and motion stay pixel-perfect. The only thing that changes between input and output is the geometry of the mouth and the immediate surrounding skin, regenerated to match the dubbed audio. Everything else is the source.
Because NEO 2 sees the full frame, it reasons about objects that occlude the face rather than treating them as part of the mouth. A microphone, a hand, a strand of hair: the model understands they are in front of the lips and preserves them across the dubbed output. Crop-based lip-sync tools can't do this because they don't see what is in front of the region they are modifying.
Dubbing is decoupled from the speech generation pipeline, so any audio track works as input. We've tested across English, Spanish, Polish, Japanese, German, French, and others. The model does not learn languages directly; it learns the visual mapping between any audio waveform and the corresponding lip and jaw motion.
Yes. NEO 2 processes frames as a sequence, not independently, so the dubbed output maintains the same motion continuity as the source. There is no per-frame flicker or temporal artefact, even on long clips. The speaker looks consistent from the first frame to the last.
Explore More
Related Research

NEO 2: Full-Body Expressive AI Avatars
The model that powers Colossyan Dubbing under the hood. Full-body, audio-driven avatar generation with consistent identity at any duration.

NEO: Expressive Talking Head Performance
The first generation of NEO. Talking-head performances with natural head movements, facial expressions, and eye gaze from audio input.