NEO 2: Full-Body Expressive AI Avatars
The talking head era is over. NEO 2 generates full-body, audio-driven avatar video with natural hand gestures, expressive upper-body animation, and consistent identity across any duration.
The Talking Head Era Is Over
For years, AI-generated avatars have shared one defining limitation: they only talk with their faces. A realistic mouth, a blinking eye, a subtle head tilt. That was considered state of the art. The result? Videos that feel oddly static, weirdly cropped, and unmistakably artificial.
When a human speaker is confident or making a critical point, their whole body reacts. Hands reinforce an argument. Posture shifts to emphasise weight. Strip that away, and no amount of lip-sync perfection can make a video feel human.
NEO 2 is a complete rethink of how we generate human animation.
What NEO 2 Actually Does
Full-body, audio-driven avatar video from a single reference image and an audio clip
Dynamic Hand Gestures
Naturally match the cadence and emotion of the spoken words.
Expressive Upper Body
Animation shifts with energy level, posture, and emphasis.
Consistent Identity
The same person, looking the same, across a video of any length.
Unlimited Duration
Generate a 30-second intro or a 30-minute course module with consistent quality.
See It in Action
Real NEO 2 output across languages, styles, and camera angles. No cherry-picking, no post-processing.
How We Built It
NEO 2 was designed specifically for long-form, expressive, audio-driven human video. The model has three tightly integrated building blocks.
1. Audio Encoder: Hearing the Intent
Before a single frame is generated, NEO 2 listens. Our Audio Encoder transforms raw speech into an embedding that captures prosody, energy, rhythm, and emphasis. The multi-scale audio representation builds on our NEO 1 model's lip-sync quality, which already ranked first on public benchmarks.
Why it matters: "I'm really excited about this," said flatly vs. with genuine enthusiasm, should produce completely different body language. Our encoding ensures the motion follows delivery, not just the words themselves.
2. Video Encoder and Decoder: Latent Space
NEO 2 operates in latent space, which is a compressed, structured representation of the visual world.
- The Encoder (VAE) compresses the reference image into an "identity anchor," telling the model what the person looks like and how they are lit.
- The Decoder reconstructs the generated latent sequence into pixel-perfect frames.
3. The DiT Block: Where Animation Happens
The core of NEO 2 is a Diffusion Transformer (DiT). It refines the signal from noise, guided by the reference image, the text prompt, and the audio embeddings. The transformer's attention mechanism processes all of these jointly, so gestures feel driven by speech rather than layered on top of it.
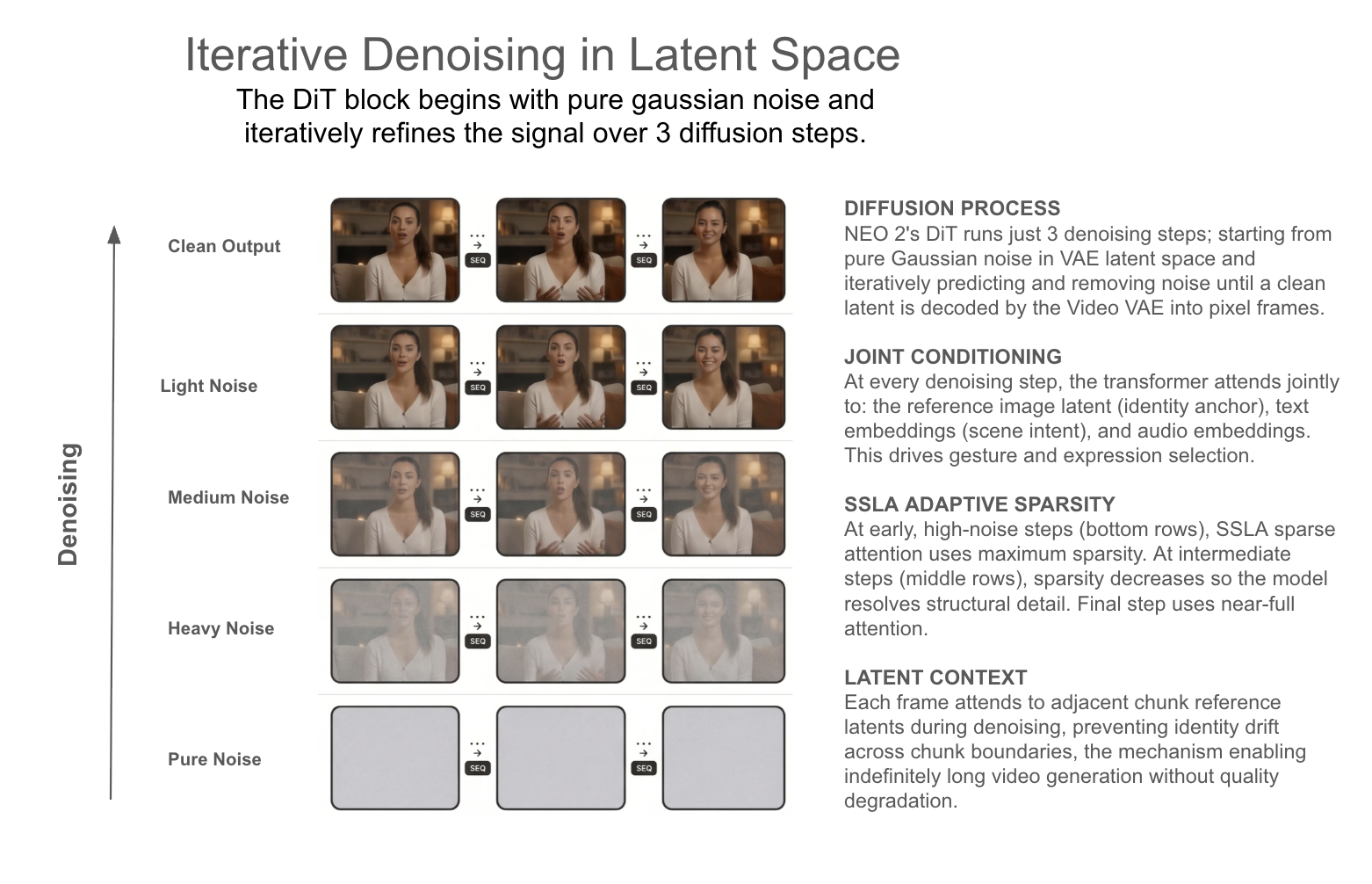
Generation at Any Length
Most video models degrade over time. Identity drifts, motion gets unstable, and the person on screen stops looking like themselves. We developed two techniques to fix this.
Neural Continuum Sync
Traditional frame-blending is obsolete. By operating natively within the latent space, our algorithm intelligently harmonizes the latent representations across video segments. This precise continuum completely eradicates structural jumps and simple opacity fades, delivering a mathematically flawless, unbroken sequence of continuous motion across all temporal boundaries.
Latent Context Strategy
Every new video chunk receives "reference latents" from previous chunks. The DiT can "see" who the person was a moment ago, so the avatar doesn't reset its posture or change appearance mid-video.
Side-by-side comparison of quality degradation vs NEO 2 results for longer duration videos.
Running Fast on Small Hardware
A model capable of full-body video generation is, by definition, large. Large models are slow and require expensive hardware. We spent months making NEO 2 fast without sacrificing quality.
3 diffusion steps
Down from the 20-50 steps typical of video diffusion models. Scheduler tuning, guidance rescaling, and noise initialisation recover quality at the lower count.
CFG and attention caching
Reuses unconditional passes and self-attention patterns across steps, cutting roughly half the forward passes at no quality cost.
Runs on a single 24GB GPU
Dynamic offloading pins model weights in CPU memory and streams blocks to the GPU on demand. Int8/float8 quantisation reduces memory footprint further.
DiT Optimisations
Hyper-Parallel Generation
Although NEO 2 generates video in temporal chunks to handle arbitrary lengths, those chunks do not need to be produced sequentially at each diffusion step. Our non-autoregressive chunking approach allows multiple chunks to be denoised in parallel using Neural Continuum Sync (NCS). This gives us both speed and quality, not a trade-off between them.
Aggressive 3-Step Diffusion
Most high-quality video diffusion models require dozens of denoising steps. We run inference in just 3, a regime that would have been considered impossibly aggressive even a year ago.
Reducing the steps to 3 was non-trivial. Simply dropping a step degraded the quality noticeably. It was made possible by the right scheduler timestep spacing, guidance rescaling, and noise level initialisation to recover quality at the lower step count. The result is a generation that is both visually compelling and extremely fast to produce.
CFG Caching and Attention Caching
Even within the small number of steps we use, there is redundancy to exploit.
- CFG cache reuses the unconditional model pass across consecutive diffusion steps when the change is below a learnable threshold. Since the unconditional output evolves very slowly, this cuts roughly half the forward passes normally required for CFG with no quality loss.
- Attention cache works at a finer granularity. Across denoising steps, self-attention patterns change slowly. We maintain a configurable schedule where certain steps compute full attention, while adjacent steps reuse the cached attention output from a nearby full step.
Supercharging the Inference
We support a spectrum of attention implementations, each with a different speed-quality trade-off:
FlashAttention 2 & 3
IO-aware fused attention kernels. Lossless and significantly faster than standard SDPA.
SageAttention
A quantised attention kernel that reduces memory bandwidth consumption with minimal quality impact.
SSLA (SageSLA)
Our most aggressive option. SSLA is a sparse attention method that identifies and attends only to the most informative tokens. We apply it adaptively across diffusion steps.
Advanced Quantisation
Selected attention layers run in float8 precision, while linear layers are reduced to int8 using dynamic quantisation (scale factors computed per-inference) or static quantisation (pre-computed from a calibration dataset) for maximum speed.
Near-Zero Overhead GPU Offloading
Model weights are pre-pinned in CPU memory. The next block is pre-fetched to the GPU via a separate CUDA stream while the current block computes. Previous blocks are freed immediately. NEO 2 runs on GPUs that would normally be considered far too small for its parameter count.
VAE Optimisations
Lazy caching reuses intermediate activations across tiled passes. Channel-last 3D memory layout (NDHWC) improves throughput for 3D convolutions. Fused RMSNorm replaces normalisation layers with a single-step kernel.
Frequently Asked Questions
NEO 2 is Colossyan's full-body avatar model. Given a single reference image and an audio clip, it generates a photorealistic video of that person speaking with natural hand gestures, posture shifts, and upper-body movement. Unlike previous avatar models that only animate the face, NEO 2 produces full-body video with consistent identity across the entire output. The model is built on a Diffusion Transformer architecture and was designed specifically for long-form video output.
NEO 1 generates talking-head performances: facial expressions, head movements, eye gaze, and lip-sync. It still ranks first on public lip-sync benchmarks. NEO 2 builds on that foundation but extends the output to the full body, adding hand gestures and upper-body animation driven directly by the audio signal. NEO 2 also uses a different generation strategy for long-form video. Open video generation models typically degrade after 5-10 seconds of output. NEO 2 uses flow field interpolation and latent context propagation to maintain visual consistency across minutes of continuous generation.
There is no architectural limit on duration. NEO 2 generates video in temporal chunks, then stitches them together using flow field interpolation in latent space. Each new chunk receives reference latents from previous chunks, so the model knows what the person looked like a moment ago. This prevents the identity drift and motion resets common in other long-form video models. A 30-second clip and a 30-minute video use the same chunked generation pipeline.
NEO 2 was designed to run on consumer-grade GPUs. Dynamic model offloading pins weights in CPU memory and streams blocks to the GPU on demand. CFG and attention caching cut forward passes roughly in half, and int8/float8 quantisation reduces memory footprint further. In practice, NEO 2 runs on a single 24GB consumer GPU. Without these optimizations, the model's parameter count would require significantly more VRAM.
The core of NEO 2 is a Diffusion Transformer (DiT) that jointly attends to audio embeddings, the reference image, and the text prompt. Because the audio encoder captures prosody, emphasis, rhythm, and energy level from the speech signal, the model generates hand and body movements that reflect the speaker's delivery. Emphatic speech produces larger, faster gestures; calm explanation produces more restrained motion. The model learns this audio-motion correlation during training through joint cross-attention between the audio encoder and visual decoder.
DiT stands for Diffusion Transformer, a denoising architecture that operates on latent patches rather than pixel space. NEO 2's DiT uses joint attention across three input modalities (image, text, audio) so that all signals influence the generated motion simultaneously. We run inference in just 3 diffusion steps, compared to the 20-50 steps typical of video diffusion models. Getting quality output at 3 steps required careful tuning of scheduler timestep spacing, guidance rescaling, and noise initialisation.
Colossyan requires explicit, verifiable consent before creating any avatar. The platform enforces consent at the pipeline level: avatar creation requires a verified consent record before generation can begin. Without a matching consent entry, the system rejects the request. Public figure likenesses are protected by default, and age restrictions are enforced. These constraints are enforced at the infrastructure level and cannot be bypassed by end users. Every avatar on the platform is linked to a consent record that enterprise admins and Colossyan's compliance team can audit.
Related Research

Beyond Lip-Sync: Robust Video Dubbing
Most lip-sync models break the moment conditions get difficult. Colossyan Dubbing handles real-world footage by feeding the full frame through NEO 2 instead of cropping the mouth, producing broadcast-quality output on raw, unprocessed video.

NEO: Expressive Talking Head Performance
The first generation of NEO. Talking-head performances with natural head movements, facial expressions, and eye gaze from audio input.